在Learning网站上看到了一个关于此问题比较好的回答,这里整理出来,分享一下。
(一)结构化数据
结构化数据(有时称为关系数据),是遵循某种严格架构的数据,因此所有数据都具有相同的字段或属性。 共享架构允许使用 SQL(结构化查询语言)等查询语言轻松搜索此类数据。 此功能使此数据样式非常适合 CRM 系统、预留和库存管理等应用程序。
结构化数据通常存储在具有行和列的数据库表中,其中键列指示表中的一行与另一个表的另一行中的数据之间的关系。 下图显示了学生和班级的数据,这些数据与他们的成绩有关。
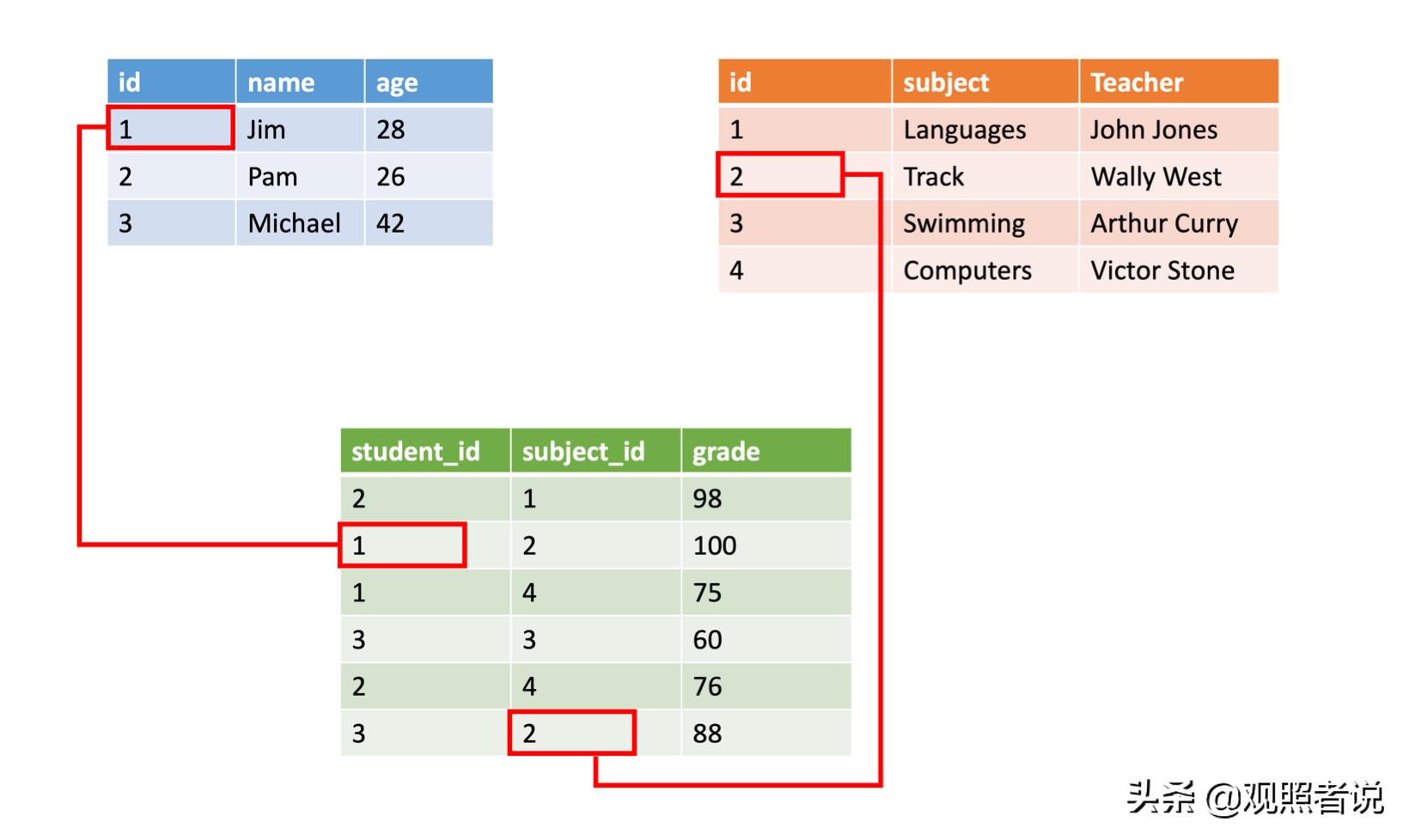
结构化数据很简单,易于输入、查询和分析。 所有数据都遵循相同的格式。 但强制采用一致的结构也意味着数据演变会更加困难,因为必须更新每个记录才能符合新的结构。
一个结构化数据的具体例子:
业务分析师希望实现商业智能,以计算库存管道和查看销售数据。 为了执行这些操作,需要将多个月的数据聚合在一起,然后进行查询。 由于需要聚合类似数据,因此必须对这些数据进行结构化处理,以便将一个月的数据与下个月的进行比较。
(二)半结构化数据
半结构化数据的组织条理性与结构化数据相比要弱,且由于字段并不完全符合表、行和列的结构,不会以关系格式存储。 半结构化数据包含突显数据的组织和层次结构的标记,例如键/值对。 半结构化数据也称为非关系数据或 NoSQL 数据。 此样式的数据的表达式和结构由序列化语言定义。
对于软件开发人员来说,数据序列化语言非常重要,因为它们可用于将存储在内存中的数据写入文件,并发送到另一个系统进行分析和读取。 发送方和接收方无需知道有关另一个系统的详细信息,只要使用同样的序列化语言,这两个系统便可以理解数据。
半结构化数据常见格式有三种:XML、JSON、YMAL。分别说明如下。
XML,即“可扩展标记语言”(extensible markup language),是首先获得广泛支持的一种数据语言。 它是基于文本的,这使得它很容易被人和机器阅读。 此外,几乎所有常用的开发平台都可以找到它的分析程序。 XML 使你可以表达关系,并具有架构、转换甚至在 Web 上显示的标准。
以下示例用 XML 表示一个人的爱好。
<Person Age=\"23\"> <FirstName>John</FirstName> <LastName>Smith</LastName> <Hobbies> <Hobby Type=\"Sports\">Golf</Hobby> <Hobby Type=\"Leisure\">Reading</Hobby> <Hobby Type=\"Leisure\">Guitar</Hobby> </Hobbies></Person>XML 非常灵活,可以轻松表达复杂数据。 但是,它往往更加冗长,从而使存储、处理或通过网络传递的规模更大。 因此,其他格式变得更加热门。
JSON,即“JavaScript 对象表示法”(JavaScript Object Notation),具有轻型规范,并依赖大括号来表示数据结构。 它没有 XML 那么冗长,且更易于阅读。 Web 服务经常使用 JSON 返回数据。
下面是以 JSON 表示同一个人。
{ \"firstName\": \"John\", \"lastName\": \"Doe\", \"age\": \"23\", \"hobbies\": [ { \"type\": \"Sports\", \"value\": \"Golf\" }, { \"type\": \"Leisure\", \"value\": \"Reading\" }, { \"type\": \"Leisure\", \"value\": \"Guitar\" } ]}请注意,此格式不像 XML 那样正式。 它比一个正式的数据表达式更接近键/值对模型。 顾名思义,JavaScript 内置了对此格式的支持,这使得它在 Web 开发中非常热门。 与 XML 一样,其他语言也有可用于处理此数据格式的分析程序。 JSON 的缺点是它更倾向于面向程序员,使得非技术人员更难阅读和修改。
YAML,即“YAML 不是一种标记语言”(YAML Ain’t Markup Language),是一种比较新式的数据语言,因为它比较人性化,所以人气迅速上涨。 数据结构由分行和缩进定义,并减少了对结构化字符(如圆括号、逗号和方括号)的依赖。
下面是以 YAML 表示的同一个人的数据。
firstName: JohnlastName: Doeage: 23hobbies: - type: Sports value: Golf - type: Leisure value: Reading - type: Leisure value: Guitar这种格式比 JSON 更具可读性,通常用于需要由人编写但由程序分析的配置文件。 然而,YAML 是最新的数据格式,在编程语言中没有 JSON 和 XML 那么多的支持。
一个半结构化数据的具体例子:
在线零售业务的产品目录数据本质上完全是结构化数据,因为每个产品都有产品 SKU、说明、数量、价格、尺寸选项、颜色选项、照片,并且可能还有视频。 因此,这些数据最初似乎具有相关性,因为它们都具有相同的结构。 但在推出新产品或不同类型的产品时,随着时间的推移,可能需要添加不同的字段。 例如,推出的新网球鞋支持蓝牙,可以将传感器数据从鞋传送到用户手机上的健身应用。 这种趋势日益上升,你希望将来能够让客户筛选“支持蓝牙”的鞋子。 你不想返回到最初阶段,更新所有现有的鞋类数据,在其中添加“支持蓝牙”属性,只想在新鞋中添加该属性。
通过添加“支持蓝牙”属性,在架构中引入了差异,因此鞋类数据不再是同源数据。 如果这是你预计会遇到的唯一例外,则可返回去将现有数据标准化,使所有产品都包含“支持蓝牙”字段,维持结构化的关系组织形式。 但是,如果这只是你预计未来需要提供支持的众多特性字段之一,则应将数据归为半结构化类型。 数据按标记组织,但目录中的每个产品都可包含唯一字段。
(三)非结构化数据
非结构化数据的组织结构难以发现。 非结构化数据通常以文件形式提供,例如照片或视频。 视频文件本身可具有整体结构并且具有半结构化元数据,但是包括视频文件本身在内的数据是非结构化数据。 因此,将照片、视频和其他类似文件归类为非结构化数据。
非结构化数据示例包括:
- 媒体文件(如照片、视频和音频文件)
- Office 文件(如 Word 文档)
- 文本文件
- 日志文件
一个非结构化数据的具体例子:
产品页面上显示的照片和视频是非结构化数据。 尽管媒体文件可能包含元数据,但媒体文件的正文是非结构化的。
概括来说,结构化数据是完全符合表中的行和列结构的组织化数据。 半结构化数据也具有组织性且有明确的属性和值,但数据存在多样性。 非结构化数据并不符合表结构,也没有架构。
